Lataa esitys
Esittely latautuu. Ole hyvä ja odota

1
Luento 2: Tilastollisen tutkimuksen peruskäsitteet ja menetelmät
Petri Nokelainen Kasvatustieteiden yksikkö Tampereen yliopisto

2
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

3
Tilastollisia käsitteitä 1.1 Sijaintiluvut
Mediaani Järjestettyjen arvojen keskimmäisin arvo (n+1)/2 Moodi Tyypillisin arvo, esiintyy useimmin Multimodaalinen
/2. Moodi. Tyypillisin arvo, esiintyy useimmin. Multimodaalinen.")
4
Tilastollisia käsitteitä 1.1 Sijaintiluvut
Keskiarvo (k.a., M) Generalized mean k = 1 aritmeettinen keskiarvo k = -1 harmoninen keskiarvo k -> 0 geometrinen keskiarvo
 Generalized mean. k = 1 aritmeettinen keskiarvo. k = -1 harmoninen keskiarvo. k -> 0 geometrinen keskiarvo.")
5
Tilastollisia käsitteitä 1.1 Sijaintiluvut

6
Tilastollisia käsitteitä 1.1 Sijaintiluvut

7
Tilastollisia käsitteitä 1.1 Sijaintiluvut
(FSD,

8
Tilastollisia käsitteitä 1.1 Sijaintiluvut
10 9 8 7 6 5 4 3 2 1 Tynnyrikuvaaja (Boxplot) Laatikon ääripäät kuvaavat kvartiileja (quartiles) Ensimmäinen kvartiili on mediaania pienempien arvojen mediaani, toinen kvartiili on itse mediaani ja kolmas kvartiili on mediaania korkeampien arvojen mediaani. Mediaani on merkitty laatikon keskellä kulkevalla viivalla Laatikon ulkopuolella olevat viivat (whiskers) kuvaavat pienintä ja suurinta havaintoa.
 Laatikon ääripäät kuvaavat kvartiileja (quartiles) Ensimmäinen kvartiili on mediaania pienempien arvojen mediaani, toinen kvartiili on itse mediaani ja kolmas kvartiili on mediaania korkeampien arvojen mediaani. Mediaani on merkitty laatikon keskellä kulkevalla viivalla. Laatikon ulkopuolella olevat viivat (whiskers) kuvaavat pienintä ja suurinta havaintoa.")
9
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

10
Tilastollisia käsitteitä 1.2 Hajontaluvut

11
Tilastollisia käsitteitä 1.2 Hajontaluvut
Keskihajonta s (k.h., SD, standard deviation) Varianssin s2 neliöjuuri: Edellyttää välimatka-asteikollista muuttujaa. Kuvaa havaintojen keskimääräistä etäisyyttä keskiarvosta. Keskihajonta säilyttää alkuperäisen mitta-asteikon tulkinnassa.
 Varianssin s2 neliöjuuri: Edellyttää välimatka-asteikollista muuttujaa. Kuvaa havaintojen keskimääräistä etäisyyttä keskiarvosta. Keskihajonta säilyttää alkuperäisen mitta-asteikon tulkinnassa.")
12
Tilastollisia käsitteitä 1.2 Hajontaluvut

13
Tilastollisia käsitteitä 1.2 Hajontaluvut
(FSD,

14
Tilastollisia käsitteitä 1.2 Hajontaluvut
Normaalijakauman oletukseen perustuvissa testeissä on syytä tarkastella otosjakauman symmetrisyyttä. Vinous g1 (skewness) kuvaa jakauman vaakapoikkeamaa oikealle tai vasemmalle verrattuna normaalijakaumaan. Huipukkuus g2 (kurtosis) kuvaa jakauman huipun muotoa. g1: oikealle ja vasemmalle vinot jakaumat g2: huipukas ja tasainen jakauma
 kuvaa jakauman vaakapoikkeamaa oikealle tai vasemmalle verrattuna normaalijakaumaan. Huipukkuus g2 (kurtosis) kuvaa jakauman huipun muotoa. g1: oikealle ja vasemmalle. vinot jakaumat. g2: huipukas ja tasainen jakauma.")
15
Esimerkki normaalista vastausjakaumasta
Esimerkki vasemmalle vinosta (negatiivisesta) ja huipukkaasta vastausjakaumasta 234 vastaajaa ovat käyttäneet kaikkia 7-portaisen vastausasteikon vastausvaihtoehtoja. Keskiarvon keskivirheen (n = /√n = 1.253/ √234 ≈ .082) avulla voidaan arvioida 95% luottamusväli annetuille vastauksille: (5.44 ± 1.96*.082). Kaksi kertaa keskivirhettä (.159) suuremman ja itseisarvoltaan 1 lähestyvän skewness (g1) arvon (-.956) perusteella voidaan päätellä että vastausjakauma on vasemmalle vino (”negatiivinen”). Kurtosis (g2) saa positiivisen, kaksi kertaa keskivirhettään (.317) suuremman arvon (.923), joten jakauman voidaan todeta olevan huipukas. Esimerkki normaalista vastausjakaumasta 234 vastaajaa ovat käyttäneet kaikkia 5-portaisen vastausasteikon vastausvaihtoehtoja. Keskiarvon keskivirheen (n = /√n = 1.099/ √234 ≈ .072) avulla voidaan arvioida 95% luottamusväli annetuille vastauksille: – 3.31 (3.17 ± 1.96*.072). Jakauma muistuttaa vaakavinoumaltaan normaalijakaumaa, koska skewness arvo (-.122) on pienempi kuin sen keskivirhe (.160). Jakauma on muodoltaan hieman tasainen, koska kurtosis saa negatiivisen arvon (-.578), mutta ei poikkea normaalista koska tuo arvo jaettuna sen keskivirheellä (.320) on pienempi kuin kaksi (-.578/.320 = 1.81).
 ja huipukkaasta vastausjakaumasta. 234 vastaajaa ovat käyttäneet kaikkia 7-portaisen vastausasteikon vastausvaihtoehtoja. Keskiarvon keskivirheen (n = /√n = 1.253/ √234 ≈ .082) avulla voidaan arvioida 95% luottamusväli annetuille vastauksille: (5.44 ± 1.96*.082). Kaksi kertaa keskivirhettä (.159) suuremman ja itseisarvoltaan 1 lähestyvän skewness (g1) arvon (-.956) perusteella voidaan päätellä että vastausjakauma on vasemmalle vino ( negatiivinen ). Kurtosis (g2) saa positiivisen, kaksi kertaa keskivirhettään (.317) suuremman arvon (.923), joten jakauman voidaan todeta olevan huipukas. Esimerkki normaalista vastausjakaumasta. 234 vastaajaa ovat käyttäneet kaikkia 5-portaisen vastausasteikon vastausvaihtoehtoja. Keskiarvon keskivirheen (n = /√n = 1.099/ √234 ≈ .072) avulla voidaan arvioida 95% luottamusväli annetuille vastauksille: 3.03 – 3.31 (3.17 ± 1.96*.072). Jakauma muistuttaa vaakavinoumaltaan normaalijakaumaa, koska skewness arvo (-.122) on pienempi kuin sen keskivirhe (.160). Jakauma on muodoltaan hieman tasainen, koska kurtosis saa negatiivisen arvon (-.578), mutta ei poikkea normaalista koska tuo arvo jaettuna sen keskivirheellä (.320) on pienempi kuin kaksi (-.578/.320 = 1.81).")
16
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

17
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
Empiiriset frekvenssijakaumat kuvaavat havaittujen mittaustulosten jakautumista. Diskreeteille muuttujille pylväsdiagrammi tai viivadiagrammi.

18
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
Empiiriset frekvenssijakaumat kuvaavat havaittujen mittaustulosten jakautumista. Jatkuville muuttujille histogrammi tai tynnyrikaavio (boxplot, laatikko-jana).
.")
19
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
Tilastolliset todennäköisyysjakaumat ovat matemaattisia malleja ilmiöiden esiintymistodennäköisyyksistä, ts. empiirisesti havaittuja ilmiöitä voidaan kuvata matemaattisten mallien avulla. Lähes kaikki tilastolliset testit perustuvat erilaisten todennäköisyysjakaumien käyttöön. Diskreettejä jakaumia: binomijakauma, Poisson –jakauma. Jatkuvia jakaumia: Normaalijakauma, Studentin t-jakauma, 2 –jakauma, F –jakauma.

20
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
Normaalijakauma Populaatio Otos s x Hajonta Odotusarvo Tilastollisessa päättelyssä yleisimmin käytetty jakauma (ns. Gaussin käyrä). Odotusarvo () ja hajonta () määrittävät jakauman muodon.
. Odotusarvo () ja hajonta () määrittävät. jakauman muodon. ")
21
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
-3 – 2.3% Standardoidun normaalijakauman odotusarvo on 0 ja keskihajonta 1. X-akselin mittayksikkönä on keskihajonta, joten voimme esim. päätellä että 68.2% havainnoista on +/- yhden keskihajonnan mitan päässä keskiarvosta.

22
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
-3 – 2.3% WAIS-R –testillä mitattujen älykkyysosamäärien keskiarvo Suomessa on 100 ja keskihajonta 15. Älykkyys on normaalisti jakautunut ominaisuus, joten testipistemäärien jakauma noudattelee normaalijakaumaan parametrein = 100 ja = 15. Saat MENSAn järjestämästä testistä pistemääräksesi 131 – miten menee?!

23
Tilastollisia käsitteitä 1.3 Todennäköisyysjakaumat
-3 – 2.3% Älykkyysosamäärä 131 sijaitsee yli kahden keskihajonnan mitan päässä keskiarvosta. Vain 2.3 prosenttia ihmisistä saa vastaavia tai korkeampia älykkyysosamääräpisteitä.

24
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

25
1.4 Hypoteesien testaaminen
Hypoteesi sisältää tutkijan ”valistuneen arvauksen” aineiston tutkimuskysymykseen antamasta vastauksesta. Hypoteesin testaamisen avulla arvioidaan, voidaanko otoksen perusteella tehdä populaatiota koskevia luotettavia päätelmiä.

26
1.4 Hypoteesien testaaminen
Nollahypoteesi (H0) tarkoittaa sitä, että aineiston antama tulos ei esiinny populaatiossa, se on syntynyt esim. epäedustavan otoksen vaikutuksesta. Vastahypoteesi (H1), tai vaihtoehtoinen hypoteesi, olettaa päinvastaista: Aineistossa esiintynyt ilmiö on löydettävissä myös populaatiosta.
 tarkoittaa sitä, että aineiston antama tulos ei esiinny populaatiossa, se on syntynyt esim. epäedustavan otoksen vaikutuksesta. Vastahypoteesi (H1), tai vaihtoehtoinen hypoteesi, olettaa päinvastaista: Aineistossa esiintynyt ilmiö on löydettävissä myös populaatiosta.")
27
1.4 Hypoteesien testaaminen
Otannalla on suuri merkitys tilastollisen tutkimuksen tulosten yleistettävyydelle: otos määrittelee sen populaation johon tulokset voidaan yleistää. Mihin populaatioon yliopisto-opiskelijoiden silmien väriä koskevat tulokset voidaan yleistää? Entäpä jos tutkitaan loogista ajattelua?

28
1.4 Hypoteesien testaaminen
Tutkimuskysymyksissä esitettyjä hypoteeseja testataan aineistosta tilastollisten testien avulla. Testit laskevat todennäköisyyden (ns. ”p-arvo”) aineistolle jos nollahypoteesi pitää paikkansa: P(D|H0). P-arvot vaihtelevat välillä 0 = epätosi .. 1 = tosi.
 aineistolle jos nollahypoteesi pitää paikkansa: P(D|H0). P-arvot vaihtelevat välillä 0 = epätosi .. 1 = tosi.")
29
1.4 Hypoteesien testaaminen
Nollahypoteesin hylkäämistä silloin kun se oikeasti pitääkin paikkansa kutsutaan tyypin yksi virheeksi (Type I error, ). Nollahypoteesin virheellinen hyväksyminen johtaa tyypin kaksi virheeseen (Type II error, ).
. Nollahypoteesin virheellinen hyväksyminen johtaa tyypin kaksi virheeseen (Type II error, ).")
30
1.4 Hypoteesien testaaminen
P-arvoille on asetettu yleisiä raja-arvoja (kriittinen -arvo), joita käytetään apuvälineinä tulkittaessa tutkimuslöydösten tilastollista merkitsevyyttä: p < .05 tilastollisesti melkein merkitsevä Tämä on yleisin merkitsevyysraja (5%). p < .01 tilastollisesti merkitsevä p < .001 tilastollisesti erittäin merkitsevä.
, joita käytetään apuvälineinä tulkittaessa tutkimuslöydösten tilastollista merkitsevyyttä: p < .05 tilastollisesti melkein merkitsevä. Tämä on yleisin merkitsevyysraja (5%). p < .01 tilastollisesti merkitsevä. p < .001 tilastollisesti erittäin merkitsevä.")
31
1.4 Hypoteesien testaaminen
Esim. jos t-testi tuottaa tulokseksi t(49)=3.4, p=.04, voidaan todeta että on olemassa vain neljän prosentin todennäköisyys saada vastaavan suuruinen ero kahden verrattavan ryhmän välille, jos otos edustaa populaatiota jossa nollahypoteesi on tosi. Vaikka kahden ryhmän välinen ero on tilastollisesti merkitsevä, se ei automaattisesti tarkoita tieteellisessä mielessä merkityksellistä eroa.
=3.4, p=.04, voidaan todeta että on olemassa vain neljän prosentin todennäköisyys saada vastaavan suuruinen ero kahden verrattavan ryhmän välille, jos otos edustaa populaatiota jossa nollahypoteesi on tosi. Vaikka kahden ryhmän välinen ero on tilastollisesti merkitsevä, se ei automaattisesti tarkoita tieteellisessä mielessä merkityksellistä eroa.")
32
1.4 Hypoteesien testaaminen
Hypoteesintestaukseen liittyy kaksi virhetyyppiä: Tyypin I virhe (Type I error, error) Oikeasti paikkansa pitävä H0 hylätään ja H1 astuu virheellisesti voimaan. Löydetään tutkimustulos jota ei oikeasti ole olemassakaan. Tyypin II virhe (Type II error, error) Oikeasti paikkansa pitävä H1 hylätään ja H0 jää virheellisesti voimaan. Tämä on ns. ”nollatutkimusta” josta usein puuttuu voima (power), mutta ei hätää – myöhempi tutkimus kyllä ennemmin tai myöhemmin löytää asioiden oikean laidan!
 Oikeasti paikkansa pitävä H0 hylätään ja H1 astuu virheellisesti voimaan. Löydetään tutkimustulos jota ei oikeasti ole olemassakaan. Tyypin II virhe (Type II error, error) Oikeasti paikkansa pitävä H1 hylätään ja H0 jää virheellisesti voimaan. Tämä on ns. nollatutkimusta josta usein puuttuu voima (power), mutta ei hätää – myöhempi tutkimus kyllä ennemmin tai myöhemmin löytää asioiden oikean laidan!")
33
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

34
2. Tilastollisten analyysimenetelmien päätyypit
Muuttujien välisten riippuvuussuhteiden voimakkuus Korreloiko vastaajien ikä työhön sitoutumista mittaavan muuttujan arvojen kanssa, ja jos korreloi, niin minkä suuntaisesti? Ryhmien välisten erojen merkitsevyys Onko eri ikäryhmien välillä eroja työhön sitoutumisessa? Ryhmäjäsenyyden ennustaminen Mitkä työhön sitoutumista mittaavat muuttujat ennustavat parhaiten mihin ikäryhmään vastaajat kuuluvat? Muuttujarakenteen mallintaminen Millaisiin ulottuvuuksiin (”faktoreihin”) käsite ”työhön sitoutuminen” on jaettavissa? Selittävätkö esimiehen johtamistaidot ja työn psyykkinen rasittavuus työhön sitoutumista?
 käsite työhön sitoutuminen on jaettavissa Selittävätkö esimiehen johtamistaidot ja työn psyykkinen rasittavuus työhön sitoutumista")
35
2. Tilastollisten analyysimenetelmien päätyypit
Muuttujien välisten riippuvuussuhteiden voimakkuus Khiin neliötesti (2), korrelaatioanalyysi (r), regressioanalyysi (R), kanoninen korrelaatioanalyysi Ryhmien välisten erojen merkitsevyys t-testi, varianssianalyysi (ANOVA), monimuuttujavarianssianalyysi (MANOVA), kovarianssianalyysi (ANCOVA) Ryhmäjäsenyyden ennustaminen Erotteluanalyysi (DA), logistinen regressioanalyysi (LOGIT), ryhmittely eli klusterianalyysi Muuttujarakenteen mallintaminen Eksploratiivinen faktorianalyysi (EFA), pääkomponenttianalyysi (PCA), rakenneyhtälömallinnus (SEM, alalajina polkuanalyysi PATH ANALYSIS ja konfirmatorinen faktorianalyysi CFA)
, korrelaatioanalyysi (r), regressioanalyysi (R), kanoninen korrelaatioanalyysi. Ryhmien välisten erojen merkitsevyys. t-testi, varianssianalyysi (ANOVA), monimuuttujavarianssianalyysi (MANOVA), kovarianssianalyysi (ANCOVA) Ryhmäjäsenyyden ennustaminen. Erotteluanalyysi (DA), logistinen regressioanalyysi (LOGIT), ryhmittely eli klusterianalyysi. Muuttujarakenteen mallintaminen. Eksploratiivinen faktorianalyysi (EFA), pääkomponenttianalyysi (PCA), rakenneyhtälömallinnus (SEM, alalajina polkuanalyysi PATH ANALYSIS ja konfirmatorinen faktorianalyysi CFA)")
36
S P S P SPSS Extension MPlus AMOS (Nokelainen, 2008.)
")
37
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

38
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Khiin neliötesti (Chi square test, 2) Millainen riippuvuussuhde on iän ja työhön sitoutumisen välillä? 1 nominaali/järjestysasteikollinen riippumaton (IV) muuttuja (ikä luokiteltuna kolmeen luokkaan) 1 nominaali/järjestysasteikollinen riippuva (DV) muuttuja (työhön sitoutuminen asteikolla 1 - 5) Olemme kiinnostuneita kuhunkin luokkaan X {X1, X2, X3} kuuluvien ihmisten vastauksista {Y1, Y2, Y3, Y4,Y5} kysymykseen Y.
 Millainen riippuvuussuhde on iän ja työhön sitoutumisen välillä 1 nominaali/järjestysasteikollinen riippumaton (IV) muuttuja (ikä luokiteltuna kolmeen luokkaan) 1 nominaali/järjestysasteikollinen riippuva (DV) muuttuja (työhön sitoutuminen asteikolla 1 - 5) Olemme kiinnostuneita kuhunkin luokkaan X {X1, X2, X3} kuuluvien ihmisten vastauksista {Y1, Y2, Y3, Y4,Y5} kysymykseen Y.")
39
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Taulukosta näemme, että tulos 2(1)= on tilastollisesti merkitsevä yhden promillen riskitasolla (p < .001).
= on. tilastollisesti merkitsevä yhden. promillen riskitasolla (p < .001).")
40
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Khiin neliön suhteellinen tulkitseminen on vaikeaa, koska sillä ei ole ylärajaa riippuvuuslukuna käytetään usein kontingenssikerrointa (C)
")
41
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Cmax ei ole 1, vaan se riippuu taulukon rivien (h) ja sarakkeiden (g) lukumäärästä seuraavan kaavan mukaisesti: , jossa k = min(g,h) k
 ja sarakkeiden (g) lukumäärästä seuraavan kaavan mukaisesti: , jossa k = min(g,h) k")
42
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Khiin neliötestin tulos Khiin neliötestin perusteella miesten ja naisten hiihto ja luistelutottumukset poikkesivat toisistaan tilastollisesti merkitsevästi, 2(1) = , p < .001, C = .48 (Cmax = 0.71). Naiset raportoivat tasaisempaa kiinnostusta kahteen edellä mainittuun talviurheilulajiin kuin miehet, jotka selvästi suosivat hiihtämistä.
 = , p < .001, C = .48 (Cmax = 0.71). Naiset raportoivat tasaisempaa kiinnostusta kahteen edellä mainittuun talviurheilulajiin kuin miehet, jotka selvästi suosivat hiihtämistä.")
43
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Raportointiesimerkkejä: Khiin neliötestin perusteella tytöt saavat poikia parempia kouluarvosanoja: 2(1) = 5.432, p = .031. 2 = Khiin neliö, (1) = vapausasteet (df, degrees of freedom), = Khiin neliötestin arvo, ei kerro muuta kuin sen, että sukupuolten välillä on eroa (poikkeaa nollasta), p = 0.31 tarkoittaa sitä, että sukupuolten välillä on tilastollisesti melkein merkitsevä ero 5 prosentin riskitasolla.
 = 5.432, p = 2 = Khiin neliö, (1) = vapausasteet (df, degrees of freedom), = Khiin neliötestin arvo, ei kerro muuta kuin sen, että sukupuolten välillä on eroa (poikkeaa nollasta), p = 0.31 tarkoittaa sitä, että sukupuolten välillä on tilastollisesti melkein merkitsevä ero 5 prosentin riskitasolla.")
44
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Raportointiesimerkkejä: Khiin neliötestin perusteella tytöt saavat poikia parempia kouluarvosanoja: C(1) = 0.39, p = .031 (Cmax = 0.71). C = Kontingenssikerroin, (1) = vapausasteet, 0.39 kertoo ryhmien välisen eron merkitsevyyden, p = .031 tarkoittaa sitä, että sukupuolten välillä on tilastollisesti merkitsevä ero 5 prosentin riskitasolla (.031 < .05), Cmax = 0.71 on tässä taulukossa ryhmien välisen eron yläraja. Kun C = 0.39, voidaan todeta, että ero ei ole tieteellisesti kovin merkittävä, vaikka onkin sitä tilastollisesti. Jos arvo olisi esim. 0.60, voisimme olla enemmän riemuissamme sukupuolten välisestä erosta (koska tällöin ollaan lähempänä ryhmien välisen eron ylärajaa 0.71).
 = 0.39, p = .031 (Cmax = 0.71). C = Kontingenssikerroin, (1) = vapausasteet, 0.39 kertoo ryhmien välisen eron merkitsevyyden, p = .031 tarkoittaa sitä, että sukupuolten välillä on tilastollisesti merkitsevä ero 5 prosentin riskitasolla (.031 < .05), Cmax = 0.71 on tässä taulukossa ryhmien välisen eron yläraja. Kun C = 0.39, voidaan todeta, että ero ei ole tieteellisesti kovin merkittävä, vaikka onkin sitä tilastollisesti. Jos arvo olisi esim. 0.60, voisimme olla enemmän riemuissamme sukupuolten välisestä erosta (koska tällöin ollaan lähempänä ryhmien välisen eron ylärajaa 0.71).")
45
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Korrelaatioanalyysi (rp tai rs) Onko iän ja työhön sitoutumisen välillä riippuvuussuhde? Jos on, niin minkä suuntainen? 2 jatkuvaa muuttujaa (rp) (ikä vuosina, työhön sitoutumista mittaavan testin pistemäärä) 2 järjestysasteikollista muuttujaa (rs) (ikä luokkina, työhön sitoutuminen asteikolla 1 – 5) Olemme kiinnostuneita kunkin vastaajan antamista vastauksista kahteen muuttujaan X ja Y.
 Onko iän ja työhön sitoutumisen välillä riippuvuussuhde Jos on, niin minkä suuntainen 2 jatkuvaa muuttujaa (rp) (ikä vuosina, työhön sitoutumista mittaavan testin pistemäärä) 2 järjestysasteikollista muuttujaa (rs) (ikä luokkina, työhön sitoutuminen asteikolla 1 – 5) Olemme kiinnostuneita kunkin vastaajan antamista vastauksista kahteen muuttujaan X ja Y.")
46
=KORRELAATIO(E7:E10,F7:F10)
")
47
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Testin nollahypoteesi (H0) = muuttujien korrelaatio perusjoukossa on 0. Tietokoneohjelmat laskevat korrelaation yhteydessä merkitsevyysluvun (p, significance) olettaen että normaalijakauman ehto täyttyy, p -arvo ilmoittaa todennäköisyyden sille että otoksesta laskettu korrelaatio on vähintään saadun suuruinen mikäli H0 pitää paikkansa ilmoittaa kuinka paljon on ”todisteita” nollahypoteesia vastaan, mitä pienempi p (0 < p < .05), sitä enemmän todisteita
 = muuttujien korrelaatio perusjoukossa on 0. Tietokoneohjelmat laskevat korrelaation yhteydessä merkitsevyysluvun (p, significance) olettaen että normaalijakauman ehto täyttyy, p -arvo. ilmoittaa todennäköisyyden sille että otoksesta laskettu korrelaatio on vähintään saadun suuruinen mikäli H0 pitää paikkansa. ilmoittaa kuinka paljon on todisteita nollahypoteesia vastaan, mitä pienempi p (0 < p < .05), sitä enemmän todisteita.")
48
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Yleinen merkitsevyystaso on 5 prosenttia p < 0.05 (5%) * tilastollisesti melkein merkitsevä p < 0.01 (1%) ** tilastollisesti merkitsevä p < (0,1%) *** tilastollisesti erittäin merkitsevä Jos luku jää etukäteen sovitun merkitsevyystason alapuolelle, H0 hylätään ja vaihtoehtoinen hypoteesi H1 hyväksytään. Ongelmana on se, että H1 ei ole ollut mukana analyyseissa eikä siten ole välttämättä H0:n vastakohta ..
 * tilastollisesti melkein merkitsevä. p < 0.01 (1%) ** tilastollisesti merkitsevä. p < (0,1%) *** tilastollisesti erittäin merkitsevä. Jos luku jää etukäteen sovitun merkitsevyystason alapuolelle, H0 hylätään ja vaihtoehtoinen hypoteesi H1 hyväksytään. Ongelmana on se, että H1 ei ole ollut mukana analyyseissa eikä siten ole välttämättä H0:n vastakohta ..")
49
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Korrelaation yhteydessä on syytä kommentoida muuttujien välistä yhteistä varianssia (coefficient of determination), joka lasketaan korottamalla korrelaatiokertoimen arvo toiseen potenssiin. Esim. jos muuttujien välillä on r = .3 suuruinen korrelaatio, niillä on 9 prosenttia (.3*.3=.09) yhteistä vaihtelua (total variance). Onko se paljon vai vähän, riippuu tutkimustehtävän luonteesta eli analyysin tuloksille asetetuista tieteellisistä oletuksista.
, joka lasketaan korottamalla korrelaatiokertoimen arvo toiseen potenssiin. Esim. jos muuttujien välillä on r = .3 suuruinen korrelaatio, niillä on 9 prosenttia (.3*.3=.09) yhteistä vaihtelua (total variance). Onko se paljon vai vähän, riippuu tutkimustehtävän luonteesta eli analyysin tuloksille asetetuista tieteellisistä oletuksista.")
50
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Cohen (1988) on lisäksi määritellyt korrelaatioille tieteellisen vaikuttavuuden (effect size) arvot: Small effect size r > 0.1 Medium effect size r > 0.3 Large effect size r > 0.5 Much larger than typical r > 0.7
 on lisäksi määritellyt korrelaatioille tieteellisen vaikuttavuuden (effect size) arvot: Small effect size r > 0.1. Medium effect size r > 0.3. Large effect size r > 0.5. Much larger than typical r > 0.7.")
51
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Pearsonin (tulomomentti) korrelaatiokerroin (rp) on tarkoitettu välimatka- ja suhdeasteikollisille muuttujille. Mittaa muuttujien välistä lineaarista yhteyttä (correlation).
 korrelaatiokerroin (rp) on tarkoitettu välimatka- ja suhdeasteikollisille muuttujille. Mittaa muuttujien välistä lineaarista yhteyttä (correlation).")
52
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Pearsonin tulomomenttikorrelaatio (rP) x:n ja y:n kovarianssi: Korrelaatiokerroin saadaan jakamalla kovarianssi x:n keskihajonnan ja y:n keskihajonnan tulolla:
 x:n ja y:n kovarianssi: Korrelaatiokerroin saadaan. jakamalla kovarianssi x:n. keskihajonnan ja y:n. keskihajonnan tulolla:")
53
SPSS –ohjelman tuloste:

54
SPSS –ohjelman tuloste:

55
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Spearmanin järjestyskorrelaatiokerroin (rs) Spearman´s Rank Order Correlation (rho) Vaatii muuttujilta vähintään järjestysasteikollista mittaustasoa -> perustuu järjestyksen vertaamiseen. Mittaa muuttujien välistä yhteyttä (association), joka voi olla lineaarista tai epälineaarista.
 Spearman´s Rank Order Correlation (rho) Vaatii muuttujilta vähintään järjestysasteikollista mittaustasoa -> perustuu järjestyksen vertaamiseen. Mittaa muuttujien välistä yhteyttä (association), joka voi olla lineaarista tai epälineaarista.")
56
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
SPSS-ohjelman tuloste:

57
2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus
Korrelaatio (rp) Varianssi (%) +/ / +/ / +/ /
 Varianssi (%) +/ / / / / /")
58
Sisältö 1. Tilastollisia käsitteitä
1.1 Sijaintiluvut 1.2 Hajontaluvut 1.3 Todennäköisyysjakaumat 1.4 Hypoteesien testaaminen 2. Tilastollisten analyysimenetelmien päätyypit 2.1 Muuttujien välisten riippuvuussuhteiden voimakkuus 2.2 Ryhmien välisten erojen merkitsevyys 2.3 Ryhmäjäsenyyden ennustaminen 2.4 Muuttujarakenteen mallintaminen

59
2.2 Ryhmien välisten erojen merkitsevyys
t-testi (t) Vertaillaan kahden ryhmän keskiarvoja. Voidaan käyttää sekä saman että erisuuruisten varianssien tapauksessa. Muuttujien tulee olla normaalisti jakautuneita. William ”Student” Gosset
 Vertaillaan kahden ryhmän keskiarvoja. Voidaan käyttää sekä saman että erisuuruisten varianssien tapauksessa. Muuttujien tulee olla normaalisti jakautuneita. William Student Gosset")
60
2.2 Ryhmien välisten erojen merkitsevyys
Riippumattomien otosten t-testi Independent-samples H0: nainen = mies

61
2.2 Ryhmien välisten erojen merkitsevyys
Riippuvien otosten t-testi Dependent-samples, paired test H0: ennen = jälkeen H0: ennen - jälkeen = 0

62
2.2 Ryhmien välisten erojen merkitsevyys
Yhden otoksen t-testi One-sample H0: = 100

64
2.2 Ryhmien välisten erojen merkitsevyys
s Otoskeskihajonta n Lukumäärä 0 Odotusarvo x Otoskeskiarvo

65
2.2 Ryhmien välisten erojen merkitsevyys Riippumattomien otosten t-testi
H0 Naiset ja miehet kokevat esimiehen arvostavan työtään yhtä paljon. H1a Sukupuolet kokevat esimiehen arvostuksen eritavoin. H1b Miehet kokevat esimiehen arvostavan työtään enemmän. H1a Kaksisuuntainen H1b Yksisuuntainen

66
2.2 Ryhmien välisten erojen merkitsevyys Riippumattomien otosten t-testi
Levenen testin avulla selvitetään ryhmien varianssien samankaltaisuutta (H0: V1 = V2) Jakaumilla on sama muoto = pooled-variance t test Levenen testin Sig. > .05 = Equal variances assumed Jakaumilla on eri muoto = separate-variance t test Levenen testin Sig. < .05 = Equal variances not assumed Vapausasteet pienenevät (=laskennassa käytetty otoskoko pienenee) erisuuruisten varianssien vuoksi. Vapausasteet pienenevät sitä enemmän mitä suuremmasta varianssien erosta on kysymys.
 Jakaumilla on sama muoto = pooled-variance t test. Levenen testin Sig. > .05 = Equal variances assumed. Jakaumilla on eri muoto = separate-variance t test. Levenen testin Sig. < .05 = Equal variances not assumed. Vapausasteet pienenevät (=laskennassa käytetty otoskoko pienenee) erisuuruisten varianssien vuoksi. Vapausasteet pienenevät sitä enemmän mitä suuremmasta varianssien erosta on kysymys.")
67
2.2 Ryhmien välisten erojen merkitsevyys Riippumattomien otosten t-testi
Sig. = p-arvo

68
2.2 Ryhmien välisten erojen merkitsevyys Riippumattomien otosten t-testi
Esimiehen arvostusta eri sukupuolten välillä vertailtiin riippumattomien otosten t-testillä. Tutkimukseen osallistui 233 miestä ja 126 naista. Tulokset osoittivat että miesten (M = 4.2, SD = .67) ja naisten (M = 3.9, SD=1.02) välillä on tilastollisesti merkitsevä ero sen suhteen, kuinka esimiehen arvostus omaa työtä kohtaan koetaan, t(357) = -2.26, p = .03.
 ja naisten (M = 3.9, SD=1.02) välillä on tilastollisesti merkitsevä ero sen suhteen, kuinka esimiehen arvostus omaa työtä kohtaan koetaan, t(357) = -2.26, p = .03.")
69
2.2 Ryhmien välisten erojen merkitsevyys Tieteellinen merkitsevyys
Effect size (efektikoko) Tuloksilla on tilastollinen ja tieteellinen merkitsevyys. Cohen (1988) ehdottaa tieteellisen merkitsevyyden arviointia seuraavien tilastollisten arvojen perusteella:
 Tuloksilla on tilastollinen ja tieteellinen merkitsevyys. Cohen (1988) ehdottaa tieteellisen merkitsevyyden arviointia seuraavien tilastollisten arvojen perusteella:")
70
2.2 Ryhmien välisten erojen merkitsevyys Tieteellinen merkitsevyys
Effect size (efektikoko) Koska edellä suoritettiin t-testi, tieteellisen merkitsevyyden arviointi voidaan suorittaa etan neliön (2) avulla: 2 = t2 t2 + (N1+N2-2) .01 = small effect .06 = moderate effect .14 = large effect
 Koska edellä suoritettiin t-testi, tieteellisen merkitsevyyden arviointi voidaan suorittaa etan neliön (2) avulla: 2 = t2. t2 + (N1+N2-2) .01 = small effect. .06 = moderate effect. .14 = large effect.")
71
2.2 Ryhmien välisten erojen merkitsevyys Tieteellinen merkitsevyys
t(357) = -2.26, p = .03 -2.262 2 = = .01 ( ) .01 = small effect .06 = moderate effect .14 = large effect
 = -2.26, p = 2 = = ( ) .01 = small effect. .06 = moderate effect. .14 = large effect.")
72
2.2 Ryhmien välisten erojen merkitsevyys Riippumattomien otosten t-testi
Esimiehen arvostusta eri sukupuolten välillä vertailtiin riippumattomien otosten t-testillä. Tutkimukseen osallistui 233 miestä ja 126 naista. Tulokset osoittivat että miesten (M = 4.22, SD = .67) ja naisten (M = 3.87, SD=1.02) välillä on tilastollisesti merkitsevä ero sen suhteen, kuinka esimiehen arvostus omaa työtä kohtaan koetaan, t(357) = -2.26, p = .03. Tulos on kuitenkin tilastollisesta merkitsevyydestä huolimatta Cohenin (1988) mukaan efektikooltaan pieni, 2 = .01.
 ja naisten (M = 3.87, SD=1.02) välillä on tilastollisesti merkitsevä ero sen suhteen, kuinka esimiehen arvostus omaa työtä kohtaan koetaan, t(357) = -2.26, p = .03. Tulos on kuitenkin tilastollisesta merkitsevyydestä huolimatta Cohenin (1988) mukaan efektikooltaan pieni, 2 = .01.")
73
2.2 Ryhmien välisten erojen merkitsevyys Mann-Whitney U, Wilcoxon W
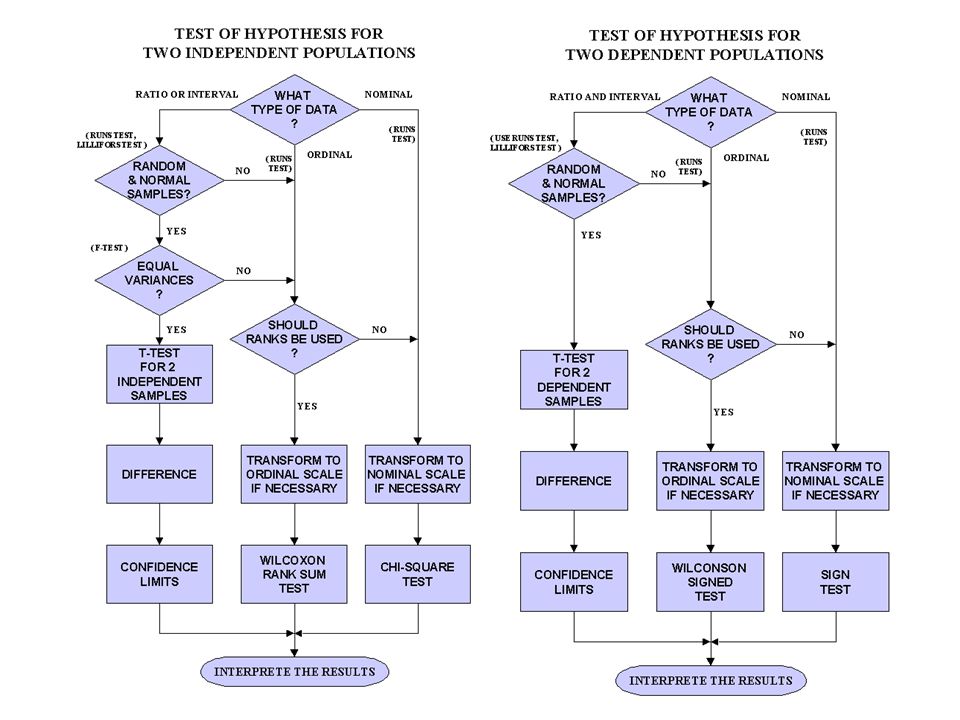
Perustuvat järjestykseen (rank), testaavat kahden mediaanin eron tilastollista merkitsevyyttä. Mittaustasovaatimuksena järjestysasteikko. Testattavien jakaumien tulee olla saman muotoisia (mutta ei normaalijakautuneita). Käytetään kun t-testin edellytykset eivät ole voimassa muuttujamuunnoksenkaan jälkeen. Epäparametriset testit sopivat t-testiä paremmin pienelle otoskoolle (esim. alle 50 havaintoa).
, testaavat kahden mediaanin eron tilastollista merkitsevyyttä. Mittaustasovaatimuksena järjestysasteikko. Testattavien jakaumien tulee olla saman muotoisia (mutta ei normaalijakautuneita). Käytetään kun t-testin edellytykset eivät ole voimassa muuttujamuunnoksenkaan jälkeen. Epäparametriset testit sopivat t-testiä paremmin pienelle otoskoolle (esim. alle 50 havaintoa).")
74
2.2 Ryhmien välisten erojen merkitsevyys Mann-Whitney U, Wilcoxon W
Lasketaan kuinka monta kertaa pienemmän otoskoon havainto on järjestyksessä suurempi kuin suuremman otoskoon havainto. Wilcoxon W Lasketaan järjestämällä kahden otoksen yhteen liitetyt havainnot ja selvittämällä pienemmän otoksen järjestyslukujen summa.

75
2.2 Ryhmien välisten erojen merkitsevyys Mann-Whitney U, Wilcoxon W
Erityispiirteitä: Summaavat vakioon Samat z arvot m pienemmän ryhmän havainnot n suuremman ryhmän havainnot m(m + 2n + 1) 2 U + W =
 2. U + W =")
76
SEX, v2 1,1,2,2,2,4,4,5 (0 = _ ) 0= = = 2,75 1= = = 6,25 11 4 25 1,5+1,5+4+4 4+6,5+6,5+8 U = N1N T1= 26-25=1 N1(N1+1) 2
 2.")
77
2.2 Ryhmien välisten erojen merkitsevyys Mann-Whitney U, Wilcoxon W
Onko naisten ja miesten välillä eroa esimiehen arvostuksen suhteen?

78
2.2 Ryhmien välisten erojen merkitsevyys Riippuvien otosten t-testi
Paired-samples t-test, repeated measures Samasta otoksesta kerätään dataa useita kertoja (eri olosuhteissa, eri aikoina). Pre-test – post-test –asetelmat Mittaus 1 – KOE – mittaus 2 Matched pairs –asetelmat Testataan uutta opetusmenetelmää kahdessa ryhmässä (toinen on kontrolli- ja toinen koeryhmä). Ryhmien jäsenet on valittu ”pareittain” koulumenestyksen ja sukupuolen perusteella. Jakson lopussa molemmat ryhmät tekevät saman testin, suorituksia verrataan pareittain.
. Pre-test – post-test –asetelmat. Mittaus 1 – KOE – mittaus 2. Matched pairs –asetelmat. Testataan uutta opetusmenetelmää kahdessa ryhmässä (toinen on kontrolli- ja toinen koeryhmä). Ryhmien jäsenet on valittu pareittain koulumenestyksen ja sukupuolen perusteella. Jakson lopussa molemmat ryhmät tekevät saman testin, suorituksia verrataan pareittain.")
79
3.29 t = t(6)=.733, p=.491 11.856 7
=.733, p= 7")
80
2.2 Ryhmien välisten erojen merkitsevyys Riippuvien otosten t-testi
Matched pairs -asetelma t = t(6)=-2.52, p=.045 7
=-2.52, p= 7.")
81
2.2 Ryhmien välisten erojen merkitsevyys Wilcoxon signed rank -test

82
2.2 Ryhmien välisten erojen merkitsevyys Friedmanin testi
Testaa nollahypoteesina sitä, että ryhmien välillä ei ole eroja = kunkin vastaajan arvot ovat sattumanvaraisia. Testin arvot jakautuvat 2 –jakauman tavoin.

83
2.2 Ryhmien välisten erojen merkitsevyys Friedmanin testi
Kuutta opiskelijaa pyydettiin asettamaan kolme eri karkkilajiketta paremmuusjärjestykseen (1,2,3). Onko karkkilajikkeiden välillä eroja?
. Onko karkkilajikkeiden välillä eroja")
84
2.2 Ryhmien välisten erojen merkitsevyys Friedmanin testi

85
2.2 Ryhmien välisten erojen merkitsevyys Yhden otoksen t-testi
Testataan yhden näytteen poikkeamaa populaation oletetusta arvosta: Kahden kontrolliryhmän (peruskoulun 5 lk.) keskiarvo tietokoneenkäyttötaitoa mittaavassa testissä on 32 pistettä. Sama testi suoritetaan tietokoneiden opetuskäytön mahdollisuuksia tutkivan kokeilukoulun viidesluokkalaisille. Tutkija haluaa selvittää poikkeaako kokeilukoulun 39 pisteen keskiarvo merkittävästi kontrollikoulujen keskiarvosta.
 keskiarvo tietokoneenkäyttötaitoa mittaavassa testissä on 32 pistettä. Sama testi suoritetaan tietokoneiden opetuskäytön mahdollisuuksia tutkivan kokeilukoulun viidesluokkalaisille. Tutkija haluaa selvittää poikkeaako kokeilukoulun 39 pisteen keskiarvo merkittävästi kontrollikoulujen keskiarvosta.")
86
2.2 Ryhmien välisten erojen merkitsevyys Yhden otoksen t-testi
Keskimääräinen älykkyysosamäärä on tutkimustulosten mukaan 100. Tämän kurssin keskiarvo on 120,7. Ovatko kurssilaiset keskimääräistä älykkäämpiä? H0: = 100

87
2.2 Ryhmien välisten erojen merkitsevyys Yhden otoksen t-testi
Tilastokurssin opiskelijoiden standardoidun älykkyystestin pistemäärää verrattiin yliopisto-opiskelijoiden keskimääräiseen älykkyystestin pistemäärään. Tulokset osoittivat että kurssin opiskelijoiden testin mittaama älykkyys (M = 120.7, SD = 23.77) on keskimääräistä (M = 100.0) korkeampi, mutta ero ei ole tilastollisesti merkitsevä, t(6) = 2.31, p = .06.
 on keskimääräistä (M = 100.0) korkeampi, mutta ero ei ole tilastollisesti merkitsevä, t(6) = 2.31, p = .06.")
88
Lähteet Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale, NJ: Erlbaum. Cronbach, L. J. (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16, Gulliksen, H. (1950). Theory of Mental Tests. New York: John Wiley & Sons. Howell, D. (1997). Statistical Methods for Psychology. Belmont, CA: Wadsworth Publishing Company.
. Coefficient alpha and the internal structure of tests. Psychometrika, 16, Gulliksen, H. (1950). Theory of Mental Tests. New York: John Wiley & Sons. Howell, D. (1997). Statistical Methods for Psychology. Belmont, CA: Wadsworth Publishing Company.")
89
Lähteet Kuder, G. F., & Richardson, M. W. (1937). The theory of the estimation of test reliability. Psychometrika, 2, Metsämuuronen, J. (2003). Tutkimuksen tekemisen perusteet ihmistieteissä. Helsinki: International Methelp Ky. Nummenmaa, L. (2009). Käyttäytymistieteiden tilastolliset menetelmät. Ensimmäinen painos, uudistettu laitos. Helsinki: Tammi. Pierce, C. A., Block, R., & Aguinis, H. (2004). Cautionary note on reporting Eta-squared values from multifactor ANOVA designs. Educational and Psychological Measurement, 64(6), Tabachnick, B ., & Fidell, L. (1996). Using Multivariate Statistics. Third Edition. New York: HarperCollins.
. Tutkimuksen tekemisen perusteet ihmistieteissä. Helsinki: International Methelp Ky. Nummenmaa, L. (2009). Käyttäytymistieteiden tilastolliset menetelmät. Ensimmäinen painos, uudistettu laitos. Helsinki: Tammi. Pierce, C. A., Block, R., & Aguinis, H. (2004). Cautionary note on reporting Eta-squared values from multifactor ANOVA designs. Educational and Psychological Measurement, 64(6), Tabachnick, B ., & Fidell, L. (1996). Using Multivariate Statistics. Third Edition. New York: HarperCollins.")
Samankaltaiset esitykset







 Testaus ei koskaan ole itsenäinen, vaan.>")


 laske normitettu arvo Gaussin käyrä>")

 -harjoitukset pääaineopiskelijoille Mira Kalalahti Käyttäytymistieteiden laitos>")






