Lataa esitys
Esittely latautuu. Ole hyvä ja odota

2
Kvantitatiiviset tutkimusmenetelmät
Luento 7 Logistinen regressioanalyysi ja lineaariset mallit Kaisu Puumalainen

3
Binäärinen logistinen regressio

4
Logistinen regressioanalyysi
selitettävä luokiteltu ja selittäjät jatkuvia (voi olla myös kategorisia) ryhmät a priori 2 ryhmää -> binary (dichotomous) logistic 3-k ryhmää -> ordinal response tai multinomial (polytomous) logistic Hosmer & Lemeshow (2000) Applied Logistic Regression, 2nd ed. New York: Wiley
 ryhmät a priori 2 ryhmää -> binary (dichotomous) logistic 3-k ryhmää -> ordinal response tai multinomial (polytomous) logistic Hosmer & Lemeshow (2000) Applied Logistic Regression, 2nd ed. New York: Wiley")
5
Sovelluksia asiakkuuden ja ei-asiakkuuden selittäminen mikä erottaa kannattavia ja ei-kannattavia yrityksiä miksi toinen tuote menestyy ja toinen ei mikä on erilaisten tekijöiden vaikutus taudin puhkeamisriskiin

6
Vaiheet tavoitteet suunnittelu edellytykset
Mitkä selittäjät vaikuttavat merkitsevästi Vaikutusten suunta ja suuruus luokittelu ryhmiin, ennustaminen suunnittelu selittäjien valinta riittävä otoskoko analyysi- ja validointiotokset edellytykset Muuttujien mittaustaso ja datan riittävyys OLS edellytyksiä ei ole

7
Vaiheet mallin estimointi ennustetarkkuuden arviointi tulkinta
enter tai stepwise, maximum likelihood ennustetarkkuuden arviointi mallin merkitsevyys selityskerroin Onnistumisprosentti luokittelussa tulkinta Kertoimet ja odds ratio validointi split sample

8
Muuttujien valinta selitettävä aidosti luokiteltu tai jatkuvasta tehty dikotominen eli binäärinen (tai 3-4 ryhmää) voidaan myös verrata vain ääriryhmiä Huom. SAS EG binäärinen vaatii, että selitettävässä ei esiinny mitään muuta kuin 2 eri arvoa (puuttuvat arvot suodatettava etukäteen) selittäjät Jatkuvia tai luokiteltuja Luokitelluille ei tarvitse tehdä erillistä dummy-muunnosta, vaan SAS tekee sen itse
 voidaan myös verrata vain ääriryhmiä Huom. SAS EG binäärinen vaatii, että selitettävässä ei esiinny mitään muuta kuin 2 eri arvoa (puuttuvat arvot suodatettava etukäteen) selittäjät Jatkuvia tai luokiteltuja Luokitelluille ei tarvitse tehdä erillistä dummy-muunnosta, vaan SAS tekee sen itse")
9
Otoksen riittävyys min 10 (miel. 20) havaintoa per selittäjä Selitettävän muuttujan joka ryhmässä väh. 20 havaintoa tai ainakin enemmän kuin selittäjiä Selitettävän muuttujan ryhmät miel. suunnilleen samankokoisia analyysiotos 50-75% ja holdout 25-50% ositettu otanta jotta ryhmäkoot säilyvät edustavina
 havaintoa per selittäjä Selitettävän muuttujan joka ryhmässä väh. 20 havaintoa tai ainakin enemmän kuin selittäjiä Selitettävän muuttujan ryhmät miel. suunnilleen samankokoisia analyysiotos 50-75% ja holdout 25-50% ositettu otanta jotta ryhmäkoot säilyvät edustavina")
10
Estimointi vaihtoehtona diskriminanttianalyysi, mutta sillä on tiukemmat taustaedellytykset Maximum likelihood-menetelmä muistuttaa tavallista regressiota Testit Epälineaarisia ja kategorisia saadaan mukaan Diagnostiikkaa Ennustaa tapahtuman todennäköisyyden p ja oddsin eli vedonlyöntisuhteen Odds = p/(1-p) eli p= odds/(1+odds)
 eli p= odds/(1+odds)")
11
Lineaarinen vs. logistinen

12
Logistinen malli

13
Esimerkki: logit= -6+.39x x logit odds P -6.00 .00 3 -4.83 .01 6 -3.66
-6.00 .00 3 -4.83 .01 6 -3.66 .03 10 -2.10 .12 .11 13 -.93 .39 .28 14 -.54 .58 .37 15 -.15 .86 .46 16 .24 1.27 .56 17 .63 1.88 .65 20 1.80 6.05 24 3.36 28.79 .97 30 5.70 298.87 1.00
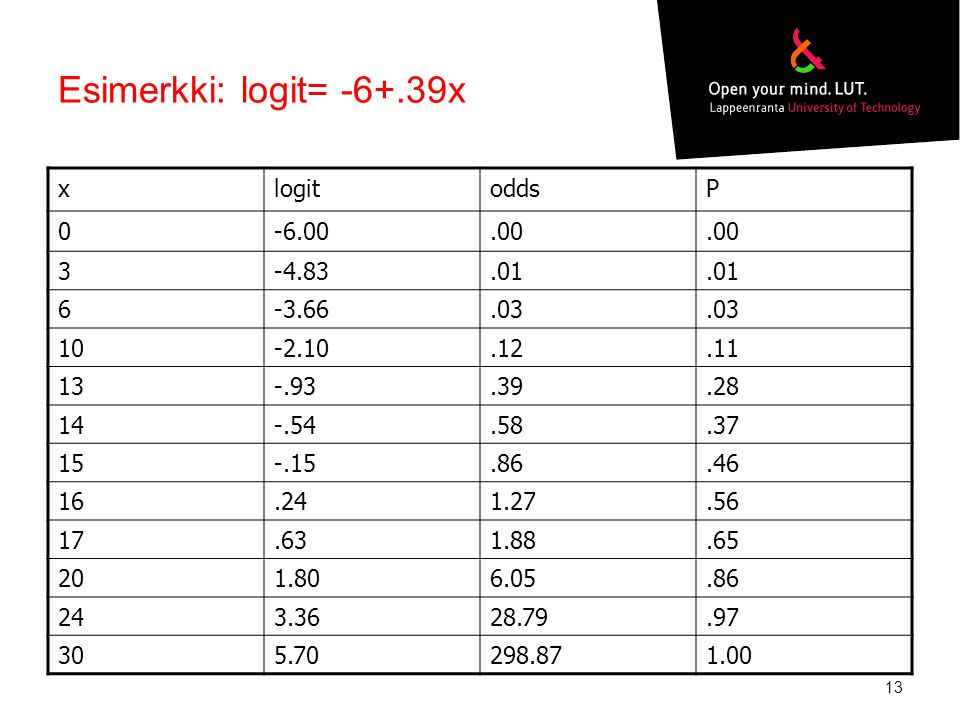
14
Esimerkki: logit= x

15
Estimointi OLS estimointi ei toimi, koska residuaalien varianssi ei ole vakio Ei analyyttista ratkaisua, vaan iteratiivinen maximum likelihood-estimointi

16
Parametriestimaatit tulkinta eroaa OLS-regressiosta: positiivinen b lisää tapahtuman todennäköisyyttä ja negatiivinen b vähentää, mutta yhteys on lineaarinen vain logitin kanssa, ei oddsin eikä todennäköisyyden!! Selittäjän Odds ratio = exp(b) = a -> kun x kasvaa yhdellä niin odds a-kertaistuu Kun x kasvaa kahdella niin odds a2-kertaistuu ”Standardoituja” kertoimia ei saa muuten kuin standardoimalla selittäjät ennen estimointia
 = a -> kun x kasvaa yhdellä niin odds a-kertaistuu Kun x kasvaa kahdella niin odds a2-kertaistuu Standardoituja kertoimia ei saa muuten kuin standardoimalla selittäjät ennen estimointia")
17
Keskivirheet ja merkitsevyys
Kertoimen b luottamusväli LCL=b - z*SEb UCL=b + z*SEb Odds ration luottamusväli eLCL …eUCL kertoimen b merkitsevyyden testaus Wald = b2 / SE2b noudattaa khi-toiseen jakaumaa df=1, jos sig.<.05 niin kerroin on merkitsevä

18
Mallin hyvyys Ei % y:n vaihtelusta kuten OLS, vaan yhteensopimattomuutta (deviance) Vertailupohjana perusmalli (base model, null model), jossa selittäjänä vain vakio Deviance-mittarina -2log likelihood (–2LL) -> minimiarvo on nolla ja pienet arvot hyviä pseudo R2 , selityskertoimet ei kerro montako % y:n vaihtelusta selittyy x:ien avulla Yleensä matalampia kuin OLS-mallin R2 Yksinkertaisin versio R2=(Dnull – Dk) / Dnull Cox&Snell maksimi alle 1 Nagelkerke ”Max-rescaled R Square” aina parempi, koska max=1
 Vertailupohjana perusmalli (base model, null model), jossa selittäjänä vain vakio Deviance-mittarina -2log likelihood (–2LL) -> minimiarvo on nolla ja pienet arvot hyviä pseudo R2 , selityskertoimet ei kerro montako % y:n vaihtelusta selittyy x:ien avulla Yleensä matalampia kuin OLS-mallin R2 Yksinkertaisin versio R2=(Dnull – Dk) / Dnull Cox&Snell maksimi alle 1 Nagelkerke Max-rescaled R Square aina parempi, koska max=1")
19
Mallin merkitsevyys OLS F-testin asemesta likelihood ratio chi square Chi square= Dnull – Dk H0:malli yhtä huono kuin nollamalli; df=k Jos sig<.05 niin malli on merkitsevä Vaihtoehtoina Wald tai Hosmer&Lemeshow (jossa H0: malli on yhteensopiva datan kanssa!)
")
20
Residuaalit Pearson ja Deviance- residuaalit Iso arvo tarkoittaa että ko. havainto sopii huonosti malliin, eli sen poisjättäminen parantaisi mallin sopivuutta dataan

21
Diagnostiikka Periaatteessa samoja kuin OLS-regressiossa Leverage (kuinka erikoinen havainto) tulkittavissa vain havainnoilla, joilla ennustettu todennäköisyys välillä .10 … .90 DFBETA (paljonko vaikuttaa kertoimiin) Cook (paljonko vaikuttaa sopivuuteen)
 tulkittavissa vain havainnoilla, joilla ennustettu todennäköisyys välillä .10 … .90 DFBETA (paljonko vaikuttaa kertoimiin) Cook (paljonko vaikuttaa sopivuuteen)")
22
Luokittelu ennustetarkkuus: ovatko havainnot luokiteltu oikeisiin ryhmiinsä Huom! Joskus hyvästäkin mallista voi tulla huono ennustetarkkuus luokittelumatriisi hit ratio: montako % luokiteltiin oikein

23
Luokittelumatriisi Ennustettu Oikea 1 Yht. Osuus oikein 40 20 60 .67 specificity 10 50 .80 sensitivity 110 80/110 .20 false neg. .33 false pos. .73 rate of correct class.

24
Luokittelu ennustetarkkuus verrattuna sattumaan yhtäsuuret ryhmät c=1/ryhmien määrä erisuuret ryhmät maximum chance criterion c= suurimman ryhmän suhteellinen osuus proportional chance criterion c=p2+(1-p)2 jos kaksi ryhmää hit ratio po. vähintään 1,25 kertaa sattumalta saatavan suuruinen
2 jos kaksi ryhmää. hit ratio po. vähintään 1,25 kertaa sattumalta saatavan suuruinen.")
25
SAS-esimerkki Aineistona pankin asiakkaat
Selitettävä muuttuja DEFAULT, luokittelu (1=maksuhäiriö, 0=ei maksuhäiriöitä) Selittäjinä Koulutus, aika samassa osoitteessa, aika samassa työpaikassa, tulot, velat suhteessa tuloihin Huom! SAS laskee puuttuvan arvon omaksi luokakseen, joten suodata analyysiin vain ne havainnot, joilla selitettävä muuttuja saa validin arvon
 Selittäjinä. Koulutus, aika samassa osoitteessa, aika samassa työpaikassa, tulot, velat suhteessa tuloihin. Huom! SAS laskee puuttuvan arvon omaksi luokakseen, joten suodata analyysiin vain ne havainnot, joilla selitettävä muuttuja saa validin arvon.")
26
Puuttuvien arvojen suodatus

27
Puuttuvien arvojen suodatus
Selitettävän muuttujan puuttuvat arvot suodatetaan pois datasta

28
SAS: analyze – regression - logistic
Dummy-koodaus Kategoriset selittäjät tänne

29
Selitettävän tiedot Tämän luokan todennäköisyyttä mallinnetaan

30
Selittäjät Valitse kaikki muuttujat ja klikkaa Main

31
Enter vai stepwise

32
Mitä tulostetaan

33
Kuvaajat

34
Mitä tallennetaan

35
SAS- koodi PROC LOGISTIC DATA=WORK.SORTTempTableSorted PLOTS(ONLY)=ALL ; CLASS ed (PARAM=REF); MODEL default (Event = '1')=employ address income debtinc ed / SELECTION=NONE INFLUENCE LACKFIT AGGREGATE SCALE=NONE RSQUARE CTABLE PPROB=(0.5) LINK=LOGIT CLPARM=BOTH CLODDS=BOTH ALPHA=0.05 OUTPUT OUT=LOGREG.PREDLogRegPredictionsFILTER_FOR_(LABEL="Logistic regression predictions and statistics for SASUSER.FILTER_FOR_BANKLOAN_SAS7BDAT") PREDPROBS=INDIVIDUAL RESCHI=reschi_default RESDEV=resdev_default DIFCHISQ=difchisq_default DIFDEV=difdev_default UPPER=upper_default LOWER=lower_default ; RUN; QUIT; Footer
=ALL ; CLASS ed (PARAM=REF); MODEL default (Event = 1 )=employ address income debtinc ed / SELECTION=NONE INFLUENCE LACKFIT AGGREGATE SCALE=NONE RSQUARE CTABLE PPROB=(0.5) LINK=LOGIT CLPARM=BOTH CLODDS=BOTH ALPHA=0.05 OUTPUT OUT=LOGREG.PREDLogRegPredictionsFILTER_FOR_(LABEL= Logistic regression predictions and statistics for SASUSER.FILTER_FOR_BANKLOAN_SAS7BDAT ) PREDPROBS=INDIVIDUAL RESCHI=reschi_default RESDEV=resdev_default DIFCHISQ=difchisq_default DIFDEV=difdev_default UPPER=upper_default LOWER=lower_default ; RUN; QUIT; Footer.")
36
Menetelmän perustiedot
Model Information Data Set WORK.SORTTEMPTABLESORT ED Response Variable default Previously defaulted Number of Response Levels 2 Model binary logit Optimization Technique Fisher's scoring Number of Observations Read 333 Number of Observations Used

37
Kategoristen muuttujien koodaus
Response Profile Ordered Value default Total Frequency 1 150 2 183 Class Level Information Class Value Design Variables ed 1 2 3 4 5 Probability modeled is default=1.

38
Mallin merkitsevyys ja sopivuus
Deviance and Pearson Goodness-of-Fit Statistics Criterio n Value DF Value/DF Pr > ChiSq Deviance 324 1.0674 0.1934 Pearson 0.9991 0.4944 Model Fit Statistics Criterion Intercept Only Intercept and Covariates AIC SC -2 Log L Tulisi olla lähellä ykköstä ja ei-merkitsevä Number of unique profiles: 333 R- Square 0.2867 Max-rescaled R- Square 0.3836 Cox-Snell Nagelkerke

39
Mallin ja selittäjien merkitsevyys
Testing Global Null Hypothesis: BETA=0 Test Chi- Square D F Pr > Chi Sq Likelihood Ratio 8 <.0001 Score Wald Type 3 Analysis of Effects Effect DF Wald Chi-Square Pr > ChiSq employ 1 <.0001 address 0.0016 income 8.9239 0.0028 debtinc ed 4 1.9037 0.7535 Mallin merkitsevyys, <.05 on merkitsevä Kunkin selittäjän merkitsevyys, <.05 on merkitsevä

40
Parametriestimaatit ja merkitsevyys
Analysis of Maximum Likelihood Estimates Parameter DF Estimate Standard Error Wald Chi-Square Pr > ChiSq Intercept 1 1.5077 0.0429 0.8359 employ 0.0357 <.0001 address 0.0230 0.0016 income 0.0204 8.9239 0.0028 debtinc 0.1395 0.0210 ed 1.5031 0.0037 0.9512 2 0.1246 1.5089 0.0068 0.9342 3 1.5305 0.0103 0.9193 4 1.5735 0.1590 0.6900 Mitä kauemmin samassa työpaikassa sitä pienempi maksuhäiriön todennäköisyys, korkein maksuhäiriön tn koulutustasolla 2 ja matalin tasolla 4 (tosin koulutus ei merkitsevä)
")
41
Odds Ratio Estimates Effect Point Estimate 95% Wald Confidence Limits employ 0.820 0.764 0.879 address 0.930 0.889 0.973 income 1.021 1.007 1.034 debtinc 1.150 1.103 1.198 ed vs 5 0.912 0.048 17.358 ed vs 5 1.133 0.059 21.800 ed vs 5 0.856 0.043 17.199 ed vs 5 0.534 0.024 11.663 Yksi vuosi lisää samassa työpaikassa pienentää maksuhäiriön oddsia 0.82-kertaiseksi Association of Predicted Probabilities and Observed Responses Percent Concordant 81.5 Somers' D 0.629 Percent Discordant 18.5 Gamma Percent Tied 0.0 Tau-a 0.312 Pairs 27450 c 0.815 Kuinka hyvin ennustettu todennäköisyys ja todellinen maksuhäiriöluokka korreloivat keskenään. D,Gamma ja tau välillä 0…1, isot hyviä

42
Parametriestimaattien luottamusvälejä
Profile Likelihood Confidence Interval for Parameters Paramete r Estimat e 95% Confidence Limit s Intercept 3.0361 employ address income 0.0204 0.0350 debtinc 0.1395 0.0999 0.1826 ed 1 3.2583 2 0.1246 3.4810 3 3.2278 4 2.8170 Profile Likelihood Confidence Interval for Odds Ratios Effect Unit Estimat e 95% Confidence Limit s employ 1.0000 0.820 0.762 0.876 address 0.930 0.888 0.972 income 1.021 1.009 1.036 debtinc 1.150 1.105 1.200 ed 1 vs 5 0.912 0.032 26.005 ed vs 5 1.133 0.040 32.491 ed vs 5 0.856 0.029 25.224 ed vs 5 0.534 0.017 16.726

43
Oddsien luottamusvälit

44
ROC- käyrä: isompi alue käyrän alapuolella -> paremmin luokitteleva malli
% of events correctly classified (% of defaults predicted as default) % of non-events incorrectly classified (% of non-def predicted as defaults)
 % of non-events incorrectly classified (% of non-def predicted as defaults)")
45
Luokittelu ja mallin sopiuvuus
Classification Table Prob Level Correct Incorrect Percentages Event Non- Event Sensi- tivity Speci- ficity False POS False NEG 0.500 140 94 56 43 70.3 76.5 62.7 28.6 31.4 Hosmer and Lemeshow Goodness-of-Fit Test Chi- Square DF Pr > ChiS q 5.2007 8 0.7359 140/ / / /137 Testaa mallin sopivuutta, H0: malli on yhteensopiva, eli p ei saisi olla <.05

46
Regression Diagnostics
Havaintojen listaus I Regression Diagnostics Case Number Covariates Pearson Residual Deviance Residual Years with current employer Years at current address Household income in thousands Debt to income ratio (x100) Level of education 1 Level of education 2 Level of education 3 Level of education 4 1 9.0000 1.0000 2 3.6000 3 4.0000 5.2000 4 6.0000 5 6.7000 6 8.0000 7 2.0000 8 3.0000 2.1000 9 10 2.9000 Havaintokohtainen listaus selittäjien arvoista ja residuaaleista. Iso residuaali tarkoittaa että mallin sopivuus paranisi paljon jos havainto jätettäisiin pois
 Level of education 1. Level of education 2. Level of education 3. Level of education Havaintokohtainen listaus selittäjien arvoista ja residuaaleista. Iso residuaali tarkoittaa että mallin sopivuus paranisi paljon jos havainto jätettäisiin pois.")
47
Havaintojen listaus II
Regression Diagnostics Case Number Hat Matrix Diagona l Intercep t DfBeta employ DfBeta address DfBeta income DfBeta debtinc DfBeta ed1 DfBeta ed2 DfBeta ed3 DfBeta ed4 DfBeta Confidence Interval Displacemen t C 1 0.0491 0.0325 -0.125 0.0429 0.0403 -0.194 -0.004 0.0007 0.0035 -0.008 0.0992 2 -0.018 -0.010 0.0125 0.0214 -0.002 -0.000 -0.001 3 0.0177 0.016 0.0617 -0.017 0.0486 -0.016 -0.003 0.0183 4 0.0111 0.0318 -0.026 0.0017 -0.060 -0.012 0.0027 0.003 0.0051 0.0210 5 0.0367 -0.074 0.0281 -0.007 0.0023 0.0028 6 0.0226 0.0160 -0.056 0.0196 0.0057 -0.079 0.0042 0.0021 0.0430 7 0.0754 0.1343 -0.098 0.0008 0.0026 -0.066 0.1235 8 0.0213 0.0053 -0.048 0.0127 0.0421 -0.005 0.0002 0.0012 9 0.0112 -0.023 0.0362 0.0234 -0.027 -0.011 0.0001 0.0151 10 0.0175 -0.019 0.0311 0.0503 -0.009 Leverage Vaikutus parametriestimaatteihin Vaikutus luottamusväleihin

48
Havaintojen listaus III
Regression Diagnostics Case Number Confidence Interval Displacement CBar Delta Deviance Delta Chi- Square 1 0.0944 2.1738 1.9228 2 0.1902 0.1002 3 0.0180 1.4003 1.0140 4 0.0207 2.1144 1.8694 5 0.4027 0.2263 6 0.0420 2.1131 1.8586 7 0.1210 4.0248 6.1630 8 0.4502 0.2545 9 0.0149 1.6951 1.3315 10 0.6625 0.3948 Vaikutus luottamusväleihin Vaikutus mallin sopivuuteen

49
Diagnostiikkaa

50
Diagnostiikkaa

51
Havaintojen vaikutus estimaatteihin

52
Havaintojen vaikutus estimaatteihin

53
Vaikuttavuus ja ennustettu arvo

54
Leverage

55
Diagnostiikkaa

56
Selittäjä vs. ennustettu p

57
Havaintojen listaus Oikea luokka Ennustettu luokka Tn että ei default
age ed emplo y addres s incom e debtin c creddeb t othdeb t defaul t Filter_ _FROM _INTO IP_0 39 1 20 9 67 30.6 3.8339 16.668 0.3535 43 12 11 38 3.6 0.1286 1.2394 0.9097 25 4 23 5.2 0.2524 0.9436 0.5009 37 6 29 16.3 1.7159 3.0111 0.3510 45 2 26 69 6.7 0.7073 3.9157 0.8210 33 8 58 18.4 3.0842 7.5878 0.3550 3 14.2 0.2049 5.0491 0.1420 15 2.1 0.1050 0.3150 0.8006 27 14.4 1.0187 2.8693 0.4316 35 2.9 0.0771 0.9379 0.7205 7 26.0 6.0489 5.6511 0.0656 30 10 22 16.1 1.4097 2.1323 0.4429 Oikea luokka Ennustettu luokka Tn että ei default

58
Havaintojen listaus IP_1 _LEVEL _ lower_defa ult upper_defa ult reschi_defa ult resdev_defa ult difdev_defa ult difchisq_defa ult 0.6464 1 1.9228 0.0902 0.1002 0.4990 1.0140 0.6489 1.8694 0.1789 0.2263 0.6449 1.8586 0.8579 6.1630 0.1994 0.2545 0.5683 1.3315 0.2794 0.3948 0.9343 0.5570 1.2973 Tn että default Luott.väli enn. tn:lle Residuaalit Vaikutus sopivuuteen

59
RAPORTOINTI Selitettävän muuttujan luonne ja linkkifunktio (binary, ordinal, multinomial) Mihin ryhmään kuulumista mallinnettiin, vertailuryhmä Mallin sopivuus: Chi-Square+p, Hosmer-Lemeshow+p, pseudo R2, hit ratiot %(total, sensitivity, specificity) Estimaatit, keskivirheet, Wald ja merkitsevyys Maininta residuaali- ja vaikuttavuustarkasteluista
 Mihin ryhmään kuulumista mallinnettiin, vertailuryhmä Mallin sopivuus: Chi-Square+p, Hosmer-Lemeshow+p, pseudo R2, hit ratiot %(total, sensitivity, specificity) Estimaatit, keskivirheet, Wald ja merkitsevyys Maininta residuaali- ja vaikuttavuustarkasteluista")
60
RAPORTOINTI, binary P(international) P(not BG|international) B S.E.
Exp(B) Novice entrepreneurs 1.300 .820 3.670 .470 .781 1.600 No int. work exp. -3.784*** 1.228 .023 19.593 3.2E08 No int. education .875 .771 2.400 1.743* .932 5.714 Novice entr.& no int. work exp. 1.231 1.544 3.424 .000 Novice entr. & no int. educ. -.932 1.223 .394 19.123 2.0E08 Constant .511 .422 1.667 -.134 .518 Model fit Chi square 29.0 (df=5), p.00 Nagelkerke R Square .378 Chi square 10.6 (df=5), p.06 Nagelkerke R Square .264 Correct classification rate international 88.2%, domestic 59.5% , overall 76.1% BG 50%, other int. 80%, overall 70.6%
 Novice entrepreneurs No int. work exp *** E08. No int. education * Novice entr.& no int. work exp Novice entr. & no int. educ E08. Constant Model fit. Chi square 29.0 (df=5), p.00. Nagelkerke R Square Chi square 10.6 (df=5), p.06. Nagelkerke R Square Correct classification rate. international 88.2%, domestic 59.5% , overall 76.1% BG 50%, other int. 80%, overall 70.6%")
61
LINEAARISET MALLIT (VARIANSSIANALYYSIT)
Oneway ANOVA, GLM Univariate (n-way ANOVA, ANCOVA)
")
62
PERUSASIAT Selitettävä muuttuja on jatkuva Selittävät muuttujat ovat kategorisia (factor, CLASS) tai jatkuvia (covariate) Onko selitettävän muuttujan keskiarvoissa eroa selittävän muuttujan ryhmien välillä Selittävien muuttujien interaktioita voidaan myös mallintaa Sopii hypoteesien testaamiseen, erityisesti käytetty kokeellisissa tutkimuksissa
 tai jatkuvia (covariate) Onko selitettävän muuttujan keskiarvoissa eroa selittävän muuttujan ryhmien välillä Selittävien muuttujien interaktioita voidaan myös mallintaa Sopii hypoteesien testaamiseen, erityisesti käytetty kokeellisissa tutkimuksissa")
63
PERUSASIAT Factor A (toimiala) Level 1 (teollisuus) Level 2 (kauppa)
Factor B (koko) Level 1 (pieni) Cell Level 2 (keskisuuri) Level 3 (suuri) 3 X 2 full factorial design (full: kaikissa soluissa on havaintoja) Balanced design: kaikissa soluissa yhtä paljon havaintoja
 Level 1 (pieni) Cell. Level 2 (keskisuuri) Level 3 (suuri) 3 X 2 full factorial design (full: kaikissa soluissa on havaintoja) Balanced design: kaikissa soluissa yhtä paljon havaintoja.")
64
EDELLYTYKSIÄ Onko kussakin ryhmässä tarpeeksi havaintoja? (miel. >20) Havaintojen riippumattomuus Varianssi-kovarianssimatriisien samanlaisuus (ei haittaa jos suurin ryhmä < 1.5*pienin ryhmä, 4* jos yhtäsuuret ryhmät) Normaalisuus Lineaarisuus Ei outlier-havaintoja
 Havaintojen riippumattomuus Varianssi-kovarianssimatriisien samanlaisuus (ei haittaa jos suurin ryhmä < 1.5*pienin ryhmä, 4* jos yhtäsuuret ryhmät) Normaalisuus Lineaarisuus Ei outlier-havaintoja")
65
VARIANSSIANALYYSIN TULKINTA
Onko malli merkitsevä? F-testi ja R square Welch, jos varianssit erisuuret (testataan Levenen tai Brown-Forsythen testillä) Minkä selittäjämuuttujien vaikutukset ovat merkitseviä? (F-testit ja partial eta squared) Mitkä ryhmät eroavat? Post hoc tai kontrastit Miten ryhmät eroavat? Estimoidut ryhmäkeskiarvot
 Minkä selittäjämuuttujien vaikutukset ovat merkitseviä (F-testit ja partial eta squared) Mitkä ryhmät eroavat Post hoc tai kontrastit Miten ryhmät eroavat Estimoidut ryhmäkeskiarvot")
66
Oneway ANOVA Yksi selitettävä jatkuva muuttuja (y) ja yksi selittävä muuttuja (x), jossa min. 3 luokkaa, luokkien määrä k Edellytyksiä: selitettävä (y) normaalijakautunut ja sen varianssit eri luokissa samat H0: y:n keskiarvot samat kaikissa x:n luokissa Vaihtelu jaetaan kahteen komponenttiin: within groups (error) ja between groups (model, treatment) -> ks. TAP prujusta kaavat Testisuure on between / within ja noudattaa F-jakaumaa vapausastein k-1, n-k Jos varianssit erisuuret, niin F-testin asemesta Welch Jos F-testi on merkitsevä, niin post hoc-testeillä katsotaan mitkä ryhmäparit poikkeavat toisistaan
 ja yksi selittävä muuttuja (x), jossa min. 3 luokkaa, luokkien määrä k Edellytyksiä: selitettävä (y) normaalijakautunut ja sen varianssit eri luokissa samat H0: y:n keskiarvot samat kaikissa x:n luokissa Vaihtelu jaetaan kahteen komponenttiin: within groups (error) ja between groups (model, treatment) -> ks. TAP prujusta kaavat Testisuure on between / within ja noudattaa F-jakaumaa vapausastein k-1, n-k Jos varianssit erisuuret, niin F-testin asemesta Welch Jos F-testi on merkitsevä, niin post hoc-testeillä katsotaan mitkä ryhmäparit poikkeavat toisistaan")
67
Multiway ANOVA, GLM Yksi jatkuva selitettävä, kaksi tai useampia luokiteltuja selittäjiä (factorial design) ANCOVA, jos jonkin jatkuvan selittäjän vaikutus halutaan eliminoida Päävaikutukset tai suorat vaikutukset (main effect) ja yhdysvaikutukset eli interaktiot fixed factor, jos kaikki mahdolliset ryhmät ovat mukana ja random factor, jos otoksessa edustettuna satunnaisesti havaintoja joistakin mahdollisista ryhmistä
 ANCOVA, jos jonkin jatkuvan selittäjän vaikutus halutaan eliminoida Päävaikutukset tai suorat vaikutukset (main effect) ja yhdysvaikutukset eli interaktiot fixed factor, jos kaikki mahdolliset ryhmät ovat mukana ja random factor, jos otoksessa edustettuna satunnaisesti havaintoja joistakin mahdollisista ryhmistä")
68
ANCOVA Mallissa mukana kovariaatti (= jatkuva selittäjä, jonka vaikutus halutaan eliminoida, esim. työkokemuksen vaikutus eliminoidaan sukupuolen ja palkan välisestä yhteydestä) Regressio kovariaatin ja selitettävän välille -> residuaalille ANOVA Kovariaatin ja selitettävän välillä oltava lineaarinen yhteys, joka on samanlainen kaikissa faktorimuuttujan ryhmissä kovariaatin ja faktoreiden välillä ei yhteyttä Kovariaatteja saa olla enintään 0.1*n – (k-1)
 Regressio kovariaatin ja selitettävän välille -> residuaalille ANOVA Kovariaatin ja selitettävän välillä oltava lineaarinen yhteys, joka on samanlainen kaikissa faktorimuuttujan ryhmissä kovariaatin ja faktoreiden välillä ei yhteyttä Kovariaatteja saa olla enintään 0.1*n – (k-1)")
69
Interaktiot Kahden faktorin yhteisvaikutus, eron suuruus yhden faktorin ryhmien välillä riippuu toisen faktorin arvosta Crossing effect = interaction effect Ordinal (keskiarvokuviossa viivat erisuuntaiset, mutta eivät leikkaa) Disordinal (keskiarvokuviossa viivat leikkaavat toisensa)
 Disordinal (keskiarvokuviossa viivat leikkaavat toisensa)")
70
Ei interaktiota Sekä koolla että toimialalla merkitsevä suora vaikutus
Ei interaktiota, homogeneity of slopes

71
Interaktiot Ordinaalinen interaktio (koon vaikutus teollisuudessa voimakkaampi kuin kaupassa) Dis-ordinaalinen interaktio (koon vaikutus teollisuudessa eri suuntainen kuin kaupassa)
")
72
Sisäkkäiset vaikutukset
Nested effect B(A) ”B nested within A” Koko (toimiala): koon vaikutus erikseen kullakin toimialalla Eroaa interaktiosta vain siinä että B:n (koko) suora vaikutus ei ole mallissa mukana B:n (koko) kulmakerroin vaihtelee A:n (toimiala) luokissa
 B nested within A Koko (toimiala): koon vaikutus erikseen kullakin toimialalla Eroaa interaktiosta vain siinä että B:n (koko) suora vaikutus ei ole mallissa mukana B:n (koko) kulmakerroin vaihtelee A:n (toimiala) luokissa")
73
Estimoidut ryhmäkeskiarvot
Estimated marginal means tai LS (least squares) means Mallin tuottamat ennustetut ryhmäkeskiarvot, kun muiden selittäjien vaikutus on otettu huomioon Eri kuin otoksesta laskettu tavallinen ryhmäkeskiarvo, jos selittäjillä on yhteyttä keskenään
 means Mallin tuottamat ennustetut ryhmäkeskiarvot, kun muiden selittäjien vaikutus on otettu huomioon Eri kuin otoksesta laskettu tavallinen ryhmäkeskiarvo, jos selittäjillä on yhteyttä keskenään")
74
Neliösummat Tyyppi I ei kontrolloi mallissa myöhemmin tulevien selittäjien vaikutuksia Tyyppi II kontrolloi kaikkien muiden selittäjien vaikutukset Tyyppi III ja IV parhaat jos soluissa eri määrät havaintoja, IV jos on tyhjiä soluja

75
Post hoc-testit Multiple comparison procedures, mean separation tests Ajatuksena on välttää I tyypin virhettä joka johtuu siitä kun tehdään monta yksittäistä parivertailua, joissa jokaisessa on 5% riskitaso niin hylkäämisvirheitä tulee Esim. Bonferroni, Scheffe, Sidak,… Tukey-Kramer muita voimakkaampi H0: ryhmäkeskiarvot samat -> jos hylätään niin ovat eri mutta jos jää voimaan niin ei välttämättä ole samat (voi johtua vaikka otoksen pienuudesta ettei päästä hylkäämään)
")
76
SAS: analyze – ANOVA – linear models

77
Estimoitavat vaikutukset
Interaktiovaikutus tästä, valitse ensin molemmat muuttujat, sitten Cross

78
Neliösummat

79
Muita optioita, tarpeeton

80
Post hoc-testit

81
Kuvaajat

82
SAS - koodi PROC GLM DATA=kirjasto.datatiedosto PLOTS(ONLY)=DIAGNOSTICS(UNPACK) PLOTS(ONLY)=RESIDUALS PLOTS(ONLY)=INTPLOT ; CLASS Elinkaari Perheyr; MODEL growthorient= ln_hlo Elinkaari Perheyr Elinkaari*Perheyr / SS3 SOLUTION SINGULAR=1E-07 LSMEANS Elinkaari Perheyr Elinkaari*Perheyr / PDIFF ADJUST=BON ; RUN; QUIT;
=DIAGNOSTICS(UNPACK) PLOTS(ONLY)=RESIDUALS PLOTS(ONLY)=INTPLOT ; CLASS Elinkaari Perheyr; MODEL growthorient= ln_hlo Elinkaari Perheyr Elinkaari*Perheyr / SS3 SOLUTION SINGULAR=1E-07 LSMEANS Elinkaari Perheyr Elinkaari*Perheyr / PDIFF ADJUST=BON ; RUN; QUIT;")
83
Mallin merkitsevyys ja sopivuus
Class Level Information Class Levels Values Elinkaari 3 2 3 4 Perheyr 2 0 1 Number of Observations Read 181 Number of Observations Used 132 Source DF Sum of Squares Mean Square F Value Pr > F Model 6 3.59 0.0026 Error 125 Corrected Total 131 R-Square Coeff Var Root MSE growthorient Mean

84
Selittäjien merkitsevyydet
Source DF Type III SS Mean Square F Value Pr > F ln_hlo 1 4.77 0.0309 Elinkaari 2 7.86 0.0006 Perheyr 0.48 0.4905 Elinkaari*Perheyr 1.64 0.1974

85
Parametriestimaatit Parameter Estimate Standard Error t Value
Pr > |t| Intercept B 6.41 <.0001 ln_hlo 2.18 0.0309 Elinkaari 0.76 0.4486 Elinkaari -0.09 0.9292 Elinkaari . Perheyr -0.93 0.3522 Perheyr Elinkaari*Perheyr 2 0 1.27 0.2065 Elinkaari*Perheyr 2 1 Elinkaari*Perheyr 3 0 0.69 0.4884 Elinkaari*Perheyr 3 1 Elinkaari*Perheyr 4 0 Elinkaari*Perheyr 4 1

86
Yhtälöt kullekin 6 solulle, esim.
Elinkaari=2 ja perheyr=0 Growth = *ln_hlo – = *ln_hlo Elinkaari=3 ja perheyr=0 Growth = *ln_hlo – 0.04 – = *ln_hlo Elinkaari=4 ja perheyr=0 Growth = *ln_hlo – = *ln_hlo Elinkaari=2 ja perheyr=1 Growth = *ln_hlo = *ln_hlo Elinkaari=3 ja perheyr=1 Growth = *ln_hlo = *ln_hlo Elinkaari=4 ja perheyr=1 Growth = *ln_hlo = *ln_hlo

87
Parametriestimaatit The X'X matrix has been found to be singular, and a generalized inverse was used to solve the normal equations. Terms whose estimates are followed by the letter 'B' are not uniquely estimable. Tämä huomautus tulee aina kun mallissa on kategorisia selittäjiä, SAS pystyy kuitenkin estimoimaan kertoimet

88
Homoskedastisuus

89
Havaintodiagnostiikkaa

90
Residuaalien jakaumat

91
Mallin sopivuus

92
Havaintojen vaikuttavuus

93
Residuaalin riippumattomuus

94
Ryhmäerojen merkitsevyys, suorat vaikutukset
Least Squares Means for effect Elinkaari Pr > |t| for H0: LSMean(i)=LSMean(j) Dependent Variable: growthorient i/j 1 2 3 0.0006 0.1225 1.0000 Elinkaari growthorient LSMEAN LSMEAN Number 2 1 3 4 Perheyr growthorient LSMEAN H0:LSMean1=LSMean 2 Pr > |t| 0.4905 1
=LSMean(j) Dependent Variable: growthorient. i/j Elinkaari. growthorient LSMEAN. LSMEAN Number Perheyr. growthorient LSMEAN. H0:LSMean1=LSMean 2. Pr > |t|")
95
Ryhmäerojen merkitsevyys, interaktiot
Elinkaari Perheyr growthorient LSMEAN LSMEAN Number 2 1 3 4 5 6 Least Squares Means for effect Elinkaari*Perheyr Pr > |t| for H0: LSMean(i)=LSMean(j) Dependent Variable: growthorient i/j 1 2 3 4 5 6 1.0000 0.0161 0.1052 0.8474 0.1040 0.8177 Kasvuvaiheen ei-perheyritykset eroavat vakiintuneen vaiheen ei-perheyrityksistä
=LSMean(j) Dependent Variable: growthorient. i/j Kasvuvaiheen ei-perheyritykset eroavat vakiintuneen vaiheen ei-perheyrityksistä.")
96
RAPORTOINTI koko mallin merkitsevyys: F-testi ja selityskerroin suorien ja interaktiovaikutusten luonne ja merkitsevyys: parametriestimaatit B estimoidut ryhmäkeskiarvot post hoc testitulokset tai kontrastitestien tulokset

97
Estimoidut ryhmäkeskiarvot
Henkilöstömäärä oletettu keskiarvoksi (20)
")
Samankaltaiset esitykset








 (New Programme – 01 September) LifePak ® (Example) - 72.60 PSV 5% Discount= €51.71 (68.97 PSV) Shipping= €4.5.>")






 Testaus ei koskaan ole itsenäinen, vaan.>")




